
PVE使用bcache加速ceph
最开始尝试使用ceph tier在进行加速ceph。
经过实际测试,这东西不行。
后来探究了OpenCAS和bcache。只因OpenCAS需要使用5.4的内核,那是pve6时代的内核,现在已经是8,自然放弃了OpenCAS,最后使用了bcache。
我们的野鸡云集群,使用5台华为2288v3 8盘6T盘作为osd,每台机器配置1块7.68t的CD6作为缓存。节点之间使用10G电口互联。
目前的架构如下:
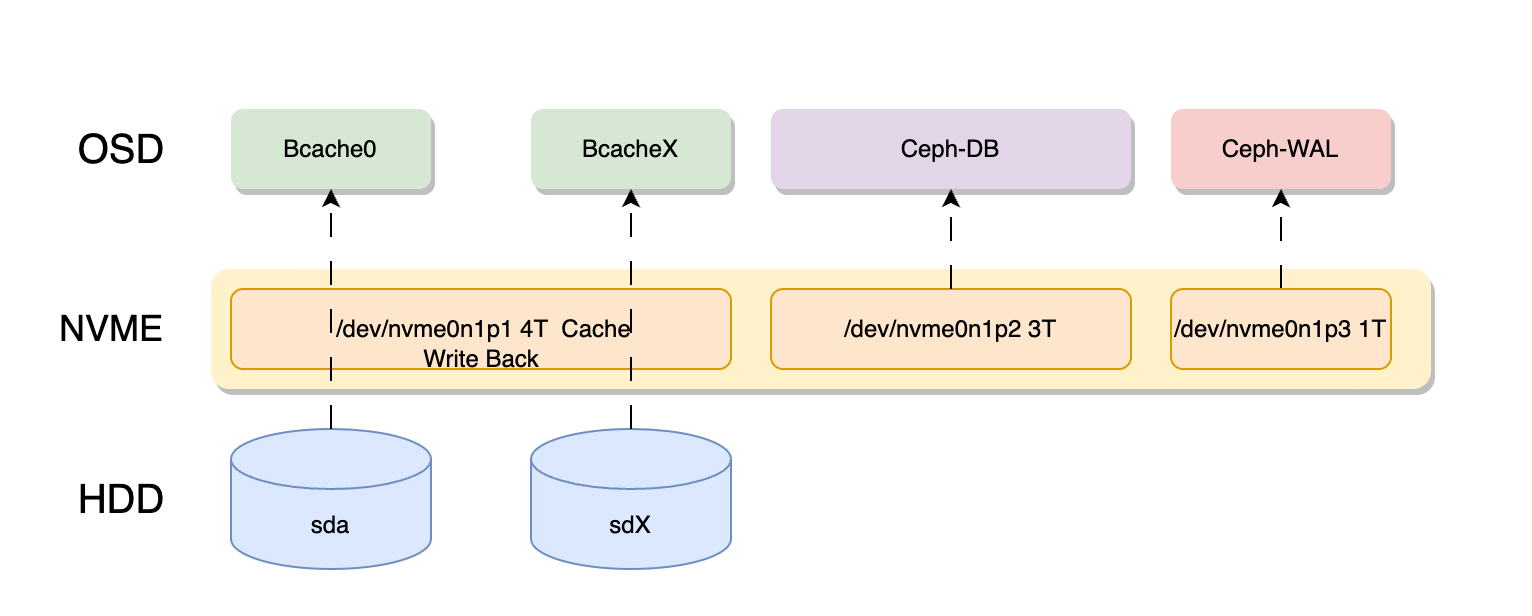
在使用rados 写入15T的数据之后,
我们可以查看bcache的命中率
root@snode2:~# cat 4.sh
for nodes in {1..5};
do
echo "snode$nodes cache_hit_ratio: "
ssh 10.0.5.$nodes cat /sys/block/bcache*/bcache/stats_total/cache_hit_ratio;
echo "______"
donesnode1 cache_hit_ratio:
99
99
99
99
98
99
99
98
______
snode2 cache_hit_ratio:
99
96
99
99
99
99
99
99
______
snode3 cache_hit_ratio:
99
99
99
99
99
99
99
99
______
snode4 cache_hit_ratio:
99
99
99
99
99
99
99
99
______
snode5 cache_hit_ratio:
99
99
99
99
99
99
99
99
使用rados进行顺序写入
root@snode2:~# rados bench -p hdd 10 write --no-cleanup
hints = 1
Maintaining 16 concurrent writes of 4194304 bytes to objects of size 4194304 for up to 10 seconds or 0 objects
Object prefix: benchmark_data_snode2_1684923
sec Cur ops started finished avg MB/s cur MB/s last lat(s) avg lat(s)
0 0 0 0 0 0 - 0
1 16 399 383 1531.92 1532 0.0322298 0.0297677
2 16 458 442 883.934 236 1.23535 0.059833
3 16 553 537 715.942 380 0.506235 0.0721879
4 16 819 803 802.925 1064 0.0388057 0.0793108
5 16 1386 1370 1095.89 2268 0.0256145 0.0582453
6 16 1519 1503 1001.9 532 0.011706 0.0576148
7 16 1795 1779 1016.47 1104 0.0123206 0.0614295
8 16 1856 1840 919.911 244 0.0174876 0.0662192
9 16 2405 2389 1061.67 2196 0.0218927 0.0601812
10 16 2638 2622 1048.7 932 0.0398509 0.0575175
Total time run: 10.4653
Total writes made: 2638
Write size: 4194304
Object size: 4194304
Bandwidth (MB/sec): 1008.28
Stddev Bandwidth: 750.973
Max bandwidth (MB/sec): 2268
Min bandwidth (MB/sec): 236
Average IOPS: 252
Stddev IOPS: 187.743
Max IOPS: 567
Min IOPS: 59
Average Latency(s): 0.0629104
Stddev Latency(s): 0.188818
Max latency(s): 1.6248
Min latency(s): 0.00889236
Cleaning up (deleting benchmark objects)
Removed 2638 objects
Clean up completed and total clean up time :0.178382在pve的ceph面板可以看到接近网络带宽的速度。
 我们再测试随机的读写
我们再测试随机的读写
root@snode2:~# rados bench -p hdd 10 rand
hints = 1
sec Cur ops started finished avg MB/s cur MB/s last lat(s) avg lat(s)
0 0 0 0 0 0 - 0
1 15 615 600 2398.46 2400 0.0154311 0.0257569
2 16 1168 1152 2303.14 2208 0.134987 0.0266897
3 15 1690 1675 2232.67 2092 0.0156014 0.027526
4 16 2143 2127 2126.48 1808 0.244971 0.0289925
5 16 2747 2731 2184.32 2416 0.0581327 0.0286238
6 15 3343 3328 2218.17 2388 0.0252261 0.028163
7 15 3954 3939 2250.31 2444 0.0282715 0.0277476
8 16 4532 4516 2257.48 2308 0.0750705 0.0276939
9 15 5159 5144 2285.67 2512 0.0130112 0.0273446
10 14 5741 5727 2290.22 2332 0.0107316 0.027296
Total time run: 10.1067
Total reads made: 5741
Read size: 4194304
Object size: 4194304
Bandwidth (MB/sec): 2272.15
Average IOPS: 568
Stddev IOPS: 52.1026
Max IOPS: 628
Min IOPS: 452
Average Latency(s): 0.0273443
Max latency(s): 0.522536
Min latency(s): 0.00347421顺序
root@snode2:~# rados bench -p hdd 10 seq
hints = 1
sec Cur ops started finished avg MB/s cur MB/s last lat(s) avg lat(s)
0 0 0 0 0 0 - 0
1 16 650 634 2535.63 2536 0.0166255 0.023774
2 15 1235 1220 2438.49 2344 0.019855 0.0255048
3 16 1855 1839 2450.9 2476 0.0455677 0.0254386
4 16 2341 2325 2324.16 1944 0.010591 0.0255989
Total time run: 4.37359
Total reads made: 2421
Read size: 4194304
Object size: 4194304
Bandwidth (MB/sec): 2214.2
Average IOPS: 553
Stddev IOPS: 66.5902
Max IOPS: 634
Min IOPS: 486
Average Latency(s): 0.0280534
Max latency(s): 1.06694
Min latency(s): 0.00492751得益于bcache的高命中缓存,成绩非常好。
反而瓶颈来到了网络,注:网卡是老板捡的一批x540t2。后期会升级到100G,全部走rdma网络和PCIE4.0。这将会发挥NVME的究极性能。
我们再尝试一下虚拟机的性能测试。
使用如下配置进行测试。
iodepth=32,jobs=16
randread-4k: (groupid=0, jobs=4): err= 0: pid=217824: Sun Jul 23 09:15:46 2023
read: IOPS=79.3k, BW=310MiB/s (325MB/s)(36.3GiB/120002msec)
randwrite-4k: (groupid=1, jobs=4): err= 0: pid=217828: Sun Jul 23 09:15:46 2023
write: IOPS=28.7k, BW=112MiB/s (117MB/s)(13.1GiB/120030msec); 0 zone resets
write-1M: (groupid=2, jobs=4): err= 0: pid=219762: Sun Jul 23 09:15:46 2023
write: IOPS=840, BW=841MiB/s (881MB/s)(98.6GiB/120106msec); 0 zone resets
read-1M: (groupid=3, jobs=4): err= 0: pid=219985: Sun Jul 23 09:15:46 2023
read: IOPS=3262, BW=3263MiB/s (3421MB/s)(383GiB/120086msec)ceph读速度一直是很快,写速度很慢。从虚拟机的表现中,随机写入有2w iops,这是一个很好的成绩。一个机械假设有500iops,40个机械也才有2w iops。
在pve上做bcache加速ceph有很明显的加速效果。毕竟bcache加速ceph是一个很成熟的方案了。但是pve的api当前不支持bcache设备,没有patch就需要自己添加bcache作为osd。
版权声明:
作者:佛西
链接:https://foxi.buduanwang.vip/virtualization/pve/2917.html/
文章版权归作者所有,未经允许请勿转载
如需获得支持,请点击网页右上角
作者:佛西
链接:https://foxi.buduanwang.vip/virtualization/pve/2917.html/
文章版权归作者所有,未经允许请勿转载
如需获得支持,请点击网页右上角
THE END
1
二维码
海报
PVE使用bcache加速ceph
最开始尝试使用ceph tier在进行加速ceph。
经过实际测试,这东西不行。
后来探究了OpenCAS和bcache。只因OpenCAS需要使用5.4的内核,那是pve6时代的内核,现在……
文章目录
关闭
ft3312591
佛西@ft3312591
ft3312591@佛西
ljzsdut
佛西@ljzsdut
Tim@佛西